Intro
小学期-空天院实习,选择的课题是:毫米波雷达手势识别算法研究,基于C3D-CNN实现。正好上个学期学习了雷达信号处理相关知识,以及深度学习,这个题目就能用上。
使用调频连续波(FMCW)雷达,对雷达回波进行2D-FFT,得到每一帧的RD图,然后使用IC3D网络进行动态的姿势识别。
随着AI时代的到来(advent),人手势识别正在吸引越来越多注意力。已经有很多的手势识别方法被提出,主要分为可穿戴式和非接触式传感器。
可穿戴式,就是在人身上穿戴加速计、磁力计和陀螺仪等,这样精准快速,但是是笨重且易丢失的。
非接触式的又能分为:视觉型、基于红外传感器(infrared)的、基于超声(ultrasonic)波的、基于电磁信号的。
视觉型的有点事不需要沉重的传感器、能快速人机交互,但确定是需要高分辨率摄像头与特定的工作环境,且使用摄像头进行识别会带来潜在的隐私风险。
红外型的并不是直接检测人手发出的红外光,而是使用可控强度(intensity)的内置红外LED灯照亮人手,接收反射回来的红外光进行识别。缺点是传感器前面有障碍物时,会影响性能。
使用无线信号的手势识别方法大多数使用WiFi信号,成本低廉且应用广泛。这种方法即使在光照不足的情况下可能实现好的识别效果,且不会危害用户隐私,但缺点是接收信号时会产生多径效应,影响估计的精度。
相比于上面这些,雷达作为手势识别的传感器,就有很多优点了。其对工作环境没有特定要求,在全天气环境下均可使用,不会危害用户隐私,且能穿墙识别。
当然,使用雷达进行手势识别也存在着一些问题,如下:
- 数据采集。使用雷达进行数据采集是较为耗时的,因此需要建立使用少量样本进行识别的模型。
- 检测和分类的同步进行。需要同时检测有无手势以及分类手势类型,避免两个动作之间出现较大延迟。
- 时空信息的提取。大部分模型没有考虑帧间信息的关联性。
- 模型复杂度。由于手势识别对计算复杂度与速度有较高要求,设计一个通用、紧凑、高效且轻量化的网络是很重要的。
本文提出的IC3D网络,在C3D的基础上减少了卷积层和全连接层的数量,同时更改了优化算法、激活函数等部分,实现了较高的准确率。
Composition of the system
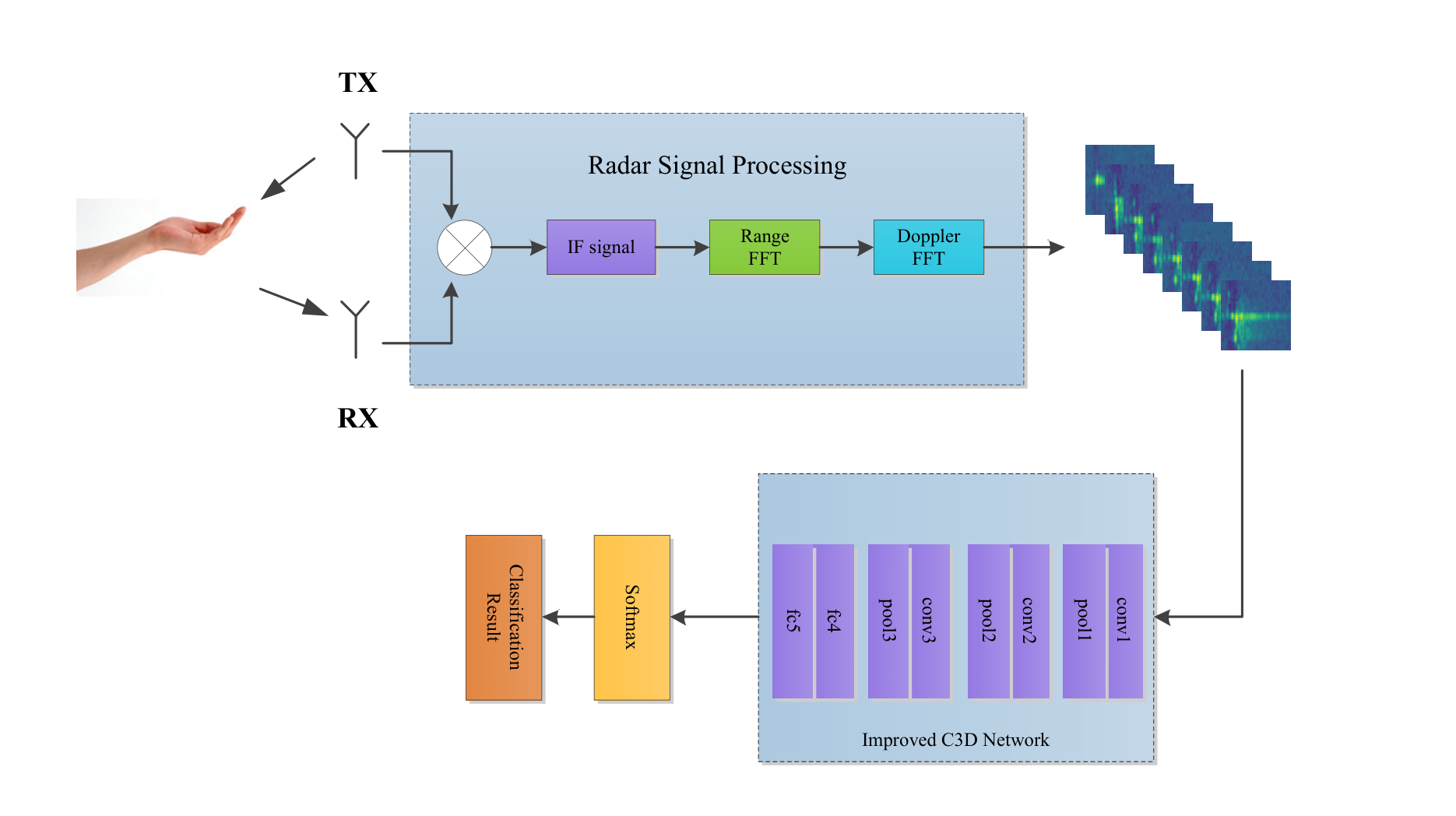
整个手势识别系统的组成如上图所示,部署在PC上,通过一台毫米波雷达采集信,经过信号处理得到RD图,再经过过IC3D网络,通过softmax层后得到结果。
Radar
雷达部分,使用锯齿波调制的FMCW雷达,也就是之前学过的Chirp信号。发射信号经过延迟$\Delta t_d$后得到回波信号。将发射信号与回波信号相乘后经过低通滤波器,即可得到稳定的IF中频信号。如下图所示:
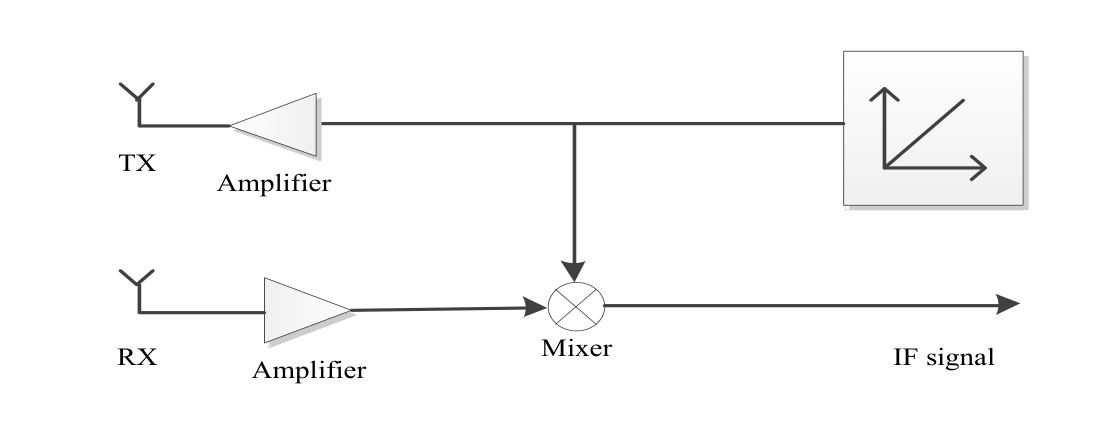
处理后得到的中频信号表达式如下所示:
$S_{IF}(t) = S_R (t) \cdot S_T(t) = \frac{1}{2}A_R A_T cos{2\pi[(f_c \cdot \Delta t_d)+(S\cdot \Delta t_d - \Delta f_d)t]}$
IF信号的形式如下图所示,其频率固定:
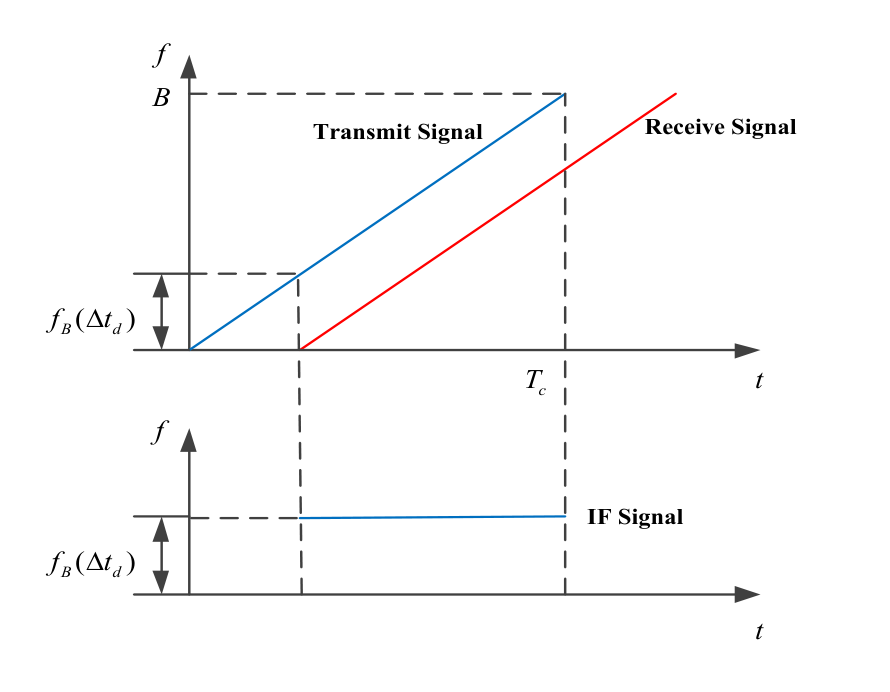
根据雷达回波能够提取出距离-速度等参数,但是这对我们不是很重要。
在参考的本篇文献中,使用的雷达是德州仪器的 IWR1642BOOST 和 DCA1000EVM 毫米波雷达。其发射波形如下图所示:
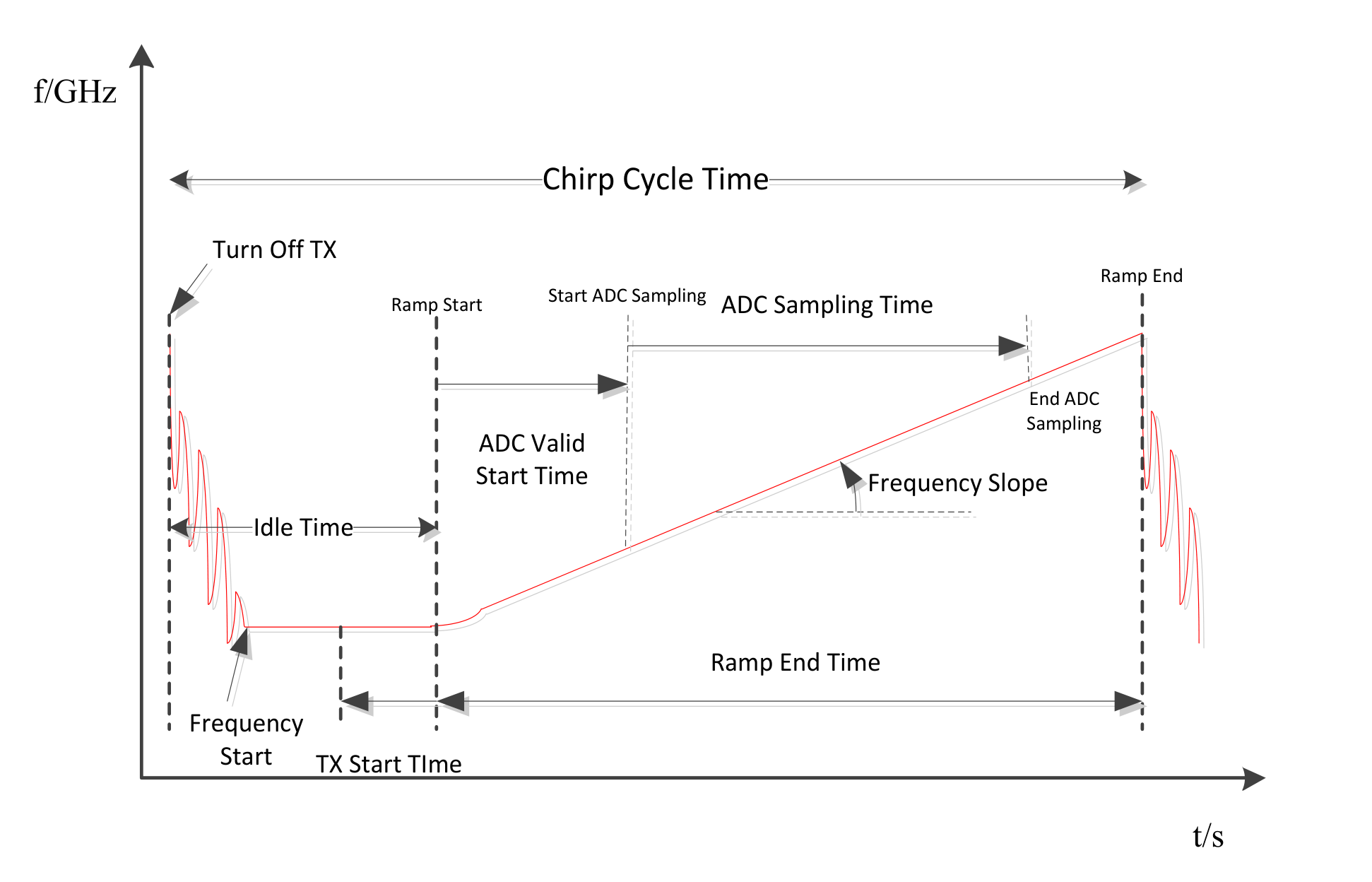
Chirp信号和采样参数的设置如下表所示:
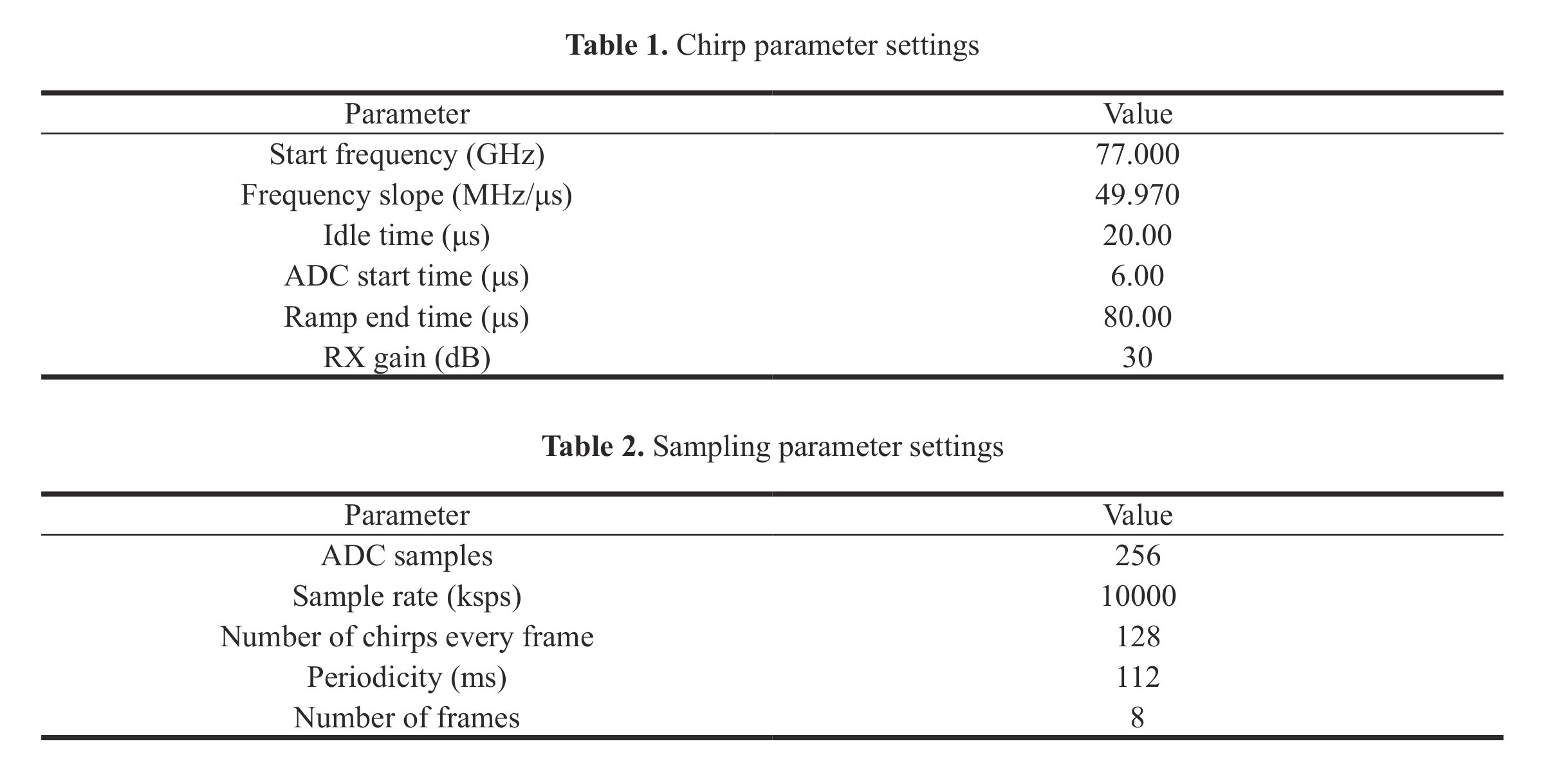
这样,一个chirp信号的时长是$100\mu s$,每帧信号中包含128个chirp,计算得一帧的时长是$12.8ms$.
但每帧的周期设置为$112ms$,因此8帧的时长为$0.896s$。
这样,每个chirp信号采256个点,每帧信号包含128个chirp,那么每帧信号的尺寸为256x128.
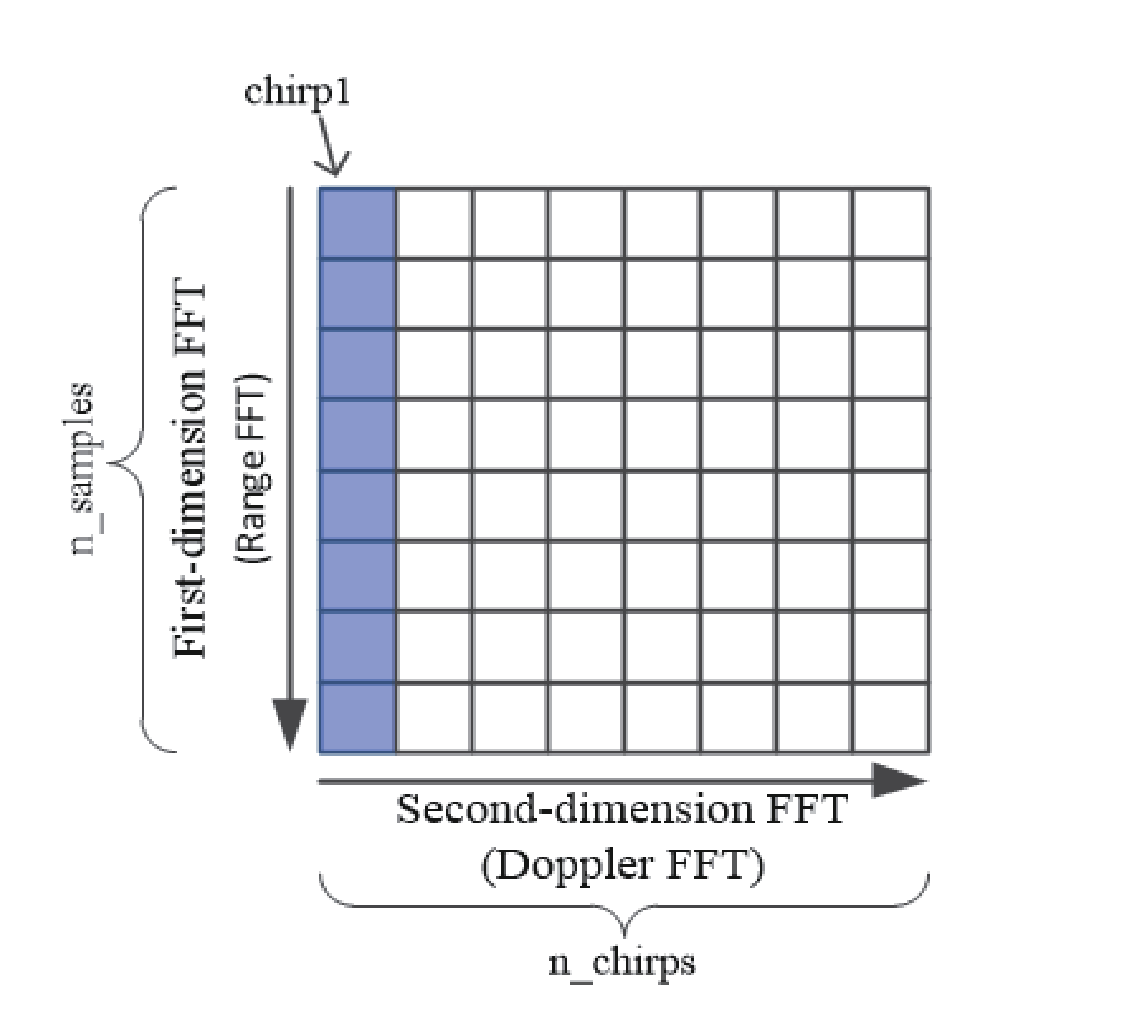
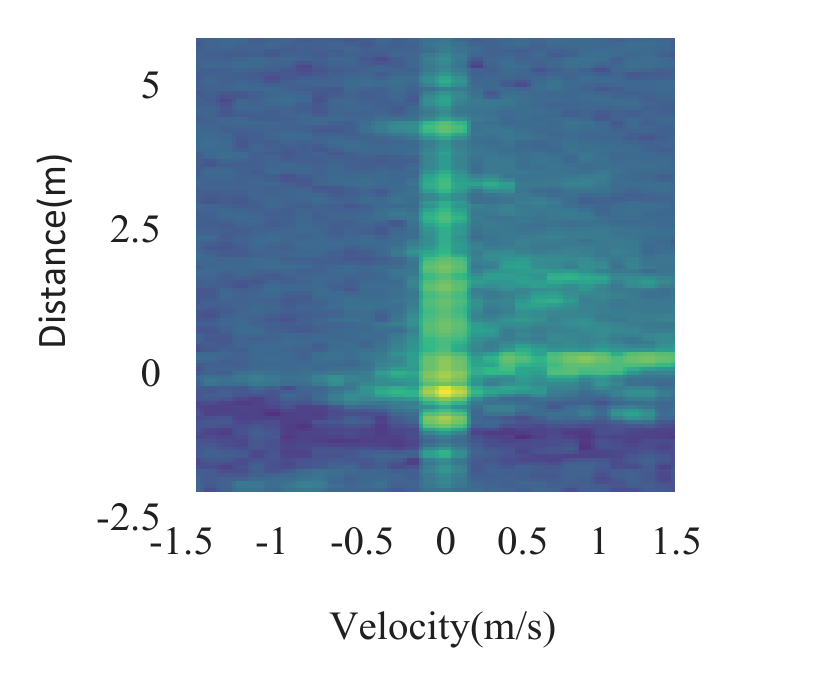
对每帧回波,先在距离维上加窗后进行一次FFT,称为距离维FFT;然后再在chirp维上进行一次FFT,称为速度维FFT。这样即可得到距离-多普勒热力图,即常说的R-D图,如下图所示:
CNN
前人的工作中,提出了3D CNN来提取时间序列信息,该网络包含 8 个卷积层、5 个池化层、2 个全连接层和 1 个 softmax 分类层。
本文中提出的改进包括以下部分:
- 减少卷积层和池化层数量。
- 降低输入参数的数量,输入尺寸降低为8帧-40x40图像。
- 采用Adam优化算法。
- 使用Mish激活函数。
最终的网络架构包括 3 个卷积层、3 个池化层、2 个全连接层以及 1 个 softmax 层。所有卷积层的卷积核大小均为 3×3×3,步幅为 1×1×1。